

小明在代码中插入了语句“df_delc=df.drop(0)”, 其余不做修改,那么运行这段修改后的代码,其运行结果为( )
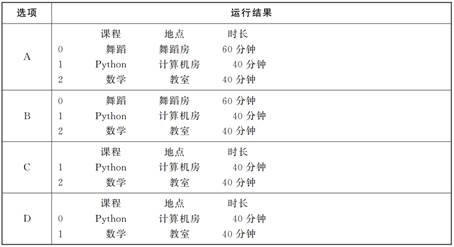
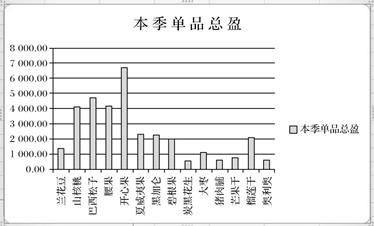
图2
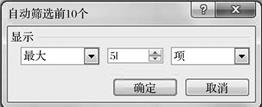
图3

图2
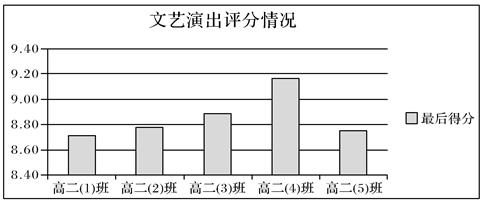
图2

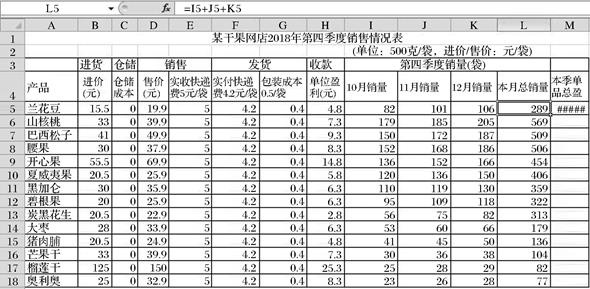
图1
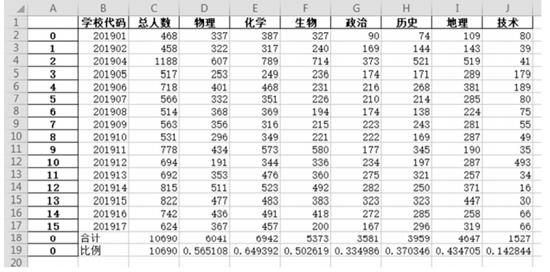
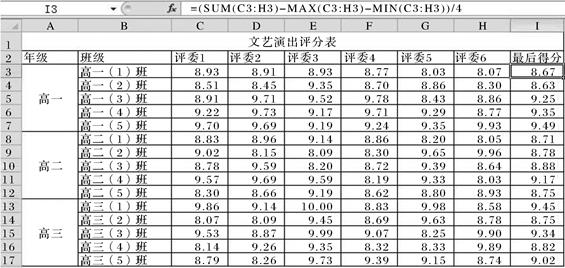
图2
实现上述功能的Python程序如下:
import pandas as pd
import itertools
#读数据到pandas的 DataFrame结构中
df= ① (”xk73.csv”,sep=‘.’,header=‘infer’,encoding=‘utf-8’)
km=[‘物理’ ,‘化学’ ,‘生物’ ,‘政治’ ,‘历史’ ,‘地理’ ,‘技术’ ]
![]()
#按学校分组计数
sc=df.groupby(‘ ② ’,as_index=False).count( )
#对分组计数结果进行合计,合计结果转换为 DF结构并转置为行
df_sum=pd.DataFrame(data=sc.sum()).T
df_sum[‘学校代码’]=‘合计’
#增加"合计"行
result=sc.append(df_sum)
#百分比计算
df_percent=df_sum
df_percent[‘学校代码’]=‘比例’
for k in km:
per=df_percent.at[0,k]/zrs
df_percent[k]=per
#增加"百分比"行
result=result.append(df_percent)
#删除"姓名"列
result= ③
#修改"学生编号"为"总人数"
result=result.rename(columns={‘学生编号’:‘总人数’})
#保存结果,创建 Excel文件.生成的 Excel文件
result.to_excel("学校人数统计.xlsx")
① ② ③