①用Python 中的循环结构编写程序
②调试运行程序,发现错误并进行修正
③设计算法:设计输入、处理、输出等一系列算法
④抽象与建模:用数学符号F(0)=F(1)=1, F(n)=F(n - 1)+F(n - 2)(n≥2,n∈N*)描述解决问题的计算模型
正确的顺序是( )

import random
list=[0]*100
count=[0]*11
for i in range(0,100):
num=random.randint(0,20)
list[i]=num
If :
num=10
count[num]+=1
print(‘0~9 及 9 以上依次出现的次数为: ’,count)
程序某次运行的结果如下:
| 0~9 及 9 以上依次出现的次数为: [3, 5, 4, 6, 5, 5, 2, 5, 9, 4, 52] |
则划线处的代码为:( )
import math
def isprime(num):
i=2
while i<=int(math.sqrt(num)):
if num % i==0:
return False
i+=1
return True
n=6
while n<=100:
for j in range(3,int(n/2)):
if :
print (n,‘=’, j,‘+’, n-j)
n+=2

import random
dict={"北京市":"北京","上海市":"上海","河北省":"石家庄",… #dict中存储中国34个省级行政区及其省会城市
sf=list( ⑴ )
sh=list( ⑵ )
sj=random.randint(0,33) #生成[0,33]之间的整数
zd=sh[sj]
del sh[sj] #删除列表 sh 中的第 sj项
xx=random.sample(sh,3)+[zd] #随机产生列表 sh 中的 3 项,与 zd 连接成新列表xx #对列表xx 中的内容进行随机排序
random.shuffle(xx)
print("%s 的省会城市是? "%( ⑶ ))
for i in range(4):
print(‘%s.%s’%(‘ABCD’ [i],xx[i]))
print(‘本题参考答案为: %s’%(‘ABCD’[ ⑷ ]))
上述程序段中方框处可选语句为:
①dict.values()
②dict.keys()
③sh[sj]
④sf[sj]
⑤xx.index(zd)
⑥xx[zd]
则( 1 )( 2 )( 3 )( 4 )处语句依次可为( )
for x in range(0,21):
for y in range(0,34):

方框内代码可以为:
if x+y+z==100 and 5*x+3*y+z/3==100:
print("鸡翁",x,"鸡母",y,"鸡雏",z)
B . for z in range(0,101,3):if x+y+z==100 and 5*x+3*y+z/3==100:
print("鸡翁",x,"鸡母",y,"鸡雏",z)
C . z=100-x-yif 5*x+3*y+z/3==100:
print("鸡翁",x,"鸡母",y,"鸡雏",z)
D . z=(100-x-y)/3if 5*x+3*y+z/3==100:
print("鸡翁",x,"鸡母",y,"鸡雏",z)

list=[[8,1,6],[3,5,7],[4,9,2]]
执行下列python程序,结果仍能构成九宫格数据的是( )
for x in range(3):
for y in range(3):
list1[x][y]=list[x-2][y]
for i in list1:
print(i)
B . list1=[[0,0,0],[0,0,0],[0,0,0]]for x in range(3):
for y in range(3):
list1[x][y]=list[y][x]
for i in list1:
print(i)
C . list1=["","",""]for x in range(3):
list1[x]=list[x][::-1]
for i in list1:
print(i)
D . list1=[[0,0,0],[0,0,0],[0,0,0]]for x in range(3):
for y in range(3):
list1[x][y]=list[y][2-x]
for i in list1:
print(i)
|
图 a |
|
图 b | 图 c |
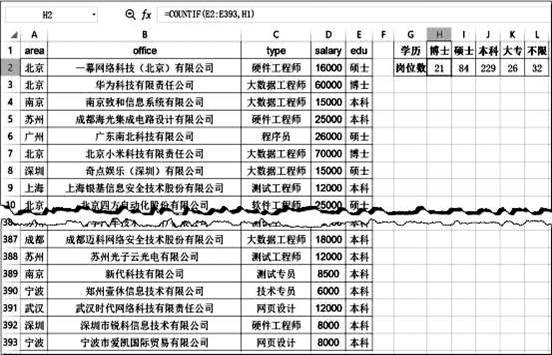
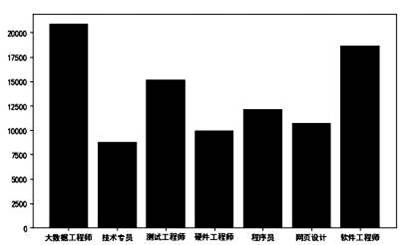
pandas as pd
import matplotlib.pyplot as plt
df=pd.read_excel("cs.xlsx")
g=df.groupby(‘type’,as_index=False)
datas=
print(round(datas,2))
name= datas[‘type’]
colleges=datas[‘salary’]
plt. (name, colleges)
plt.show( )

from PIL import Image
x_start = 11 # 起始点坐标
y_start = 92
fill_width= 24 信息点宽度
fill_height= 10 # 信息点高度
space_width = 15 间隔宽度
space_height = 12 # 间隔高度
ans_cnt = 5 # 题目个数
def bw_judge(R, G, B): # bw_judge用于判断一个像素的填涂情况
Gray_scale = 0.299 * R + 0.587 * G + 0.114 * B
return Gray_scale < 132
def fill_judge(x, y): # fill_judge 用于判断信息点的填涂情况
count = 0
for i in range(x, x + fill_width):
for j in range( ):
R, G, B = pixels[i, j]
if bw_judge(R, G, B) == True:
count = count + 1
if count >= fill_width * fill_height * 0.64:
return True
total_width = fill_width + space_width
total_height = fill_height + space_height
image = Image.open ("card.bmp")
pixels = image.load()
ans = ""
item=[‘A’,’B’,’C’,’D’]
list=[]
for col in range(ans_cnt):
x =
for row in range(4):
y = y_start + total_height * row
if fill_judge(x, y) == True:
list.append(ans)
ans=""
print(list)
|
图 a 图 b |
def showmax(ips): #统计出现次数最多的 IP 地址和出现次数
dic={}
maxn=0
for i in range(len(ips)):
if ips[i] in dic:
dic[ips[i]]+=1
if :
maxn=dic[ips[i]]
maxIp=ips[i]
else:
return maxIp,maxn
with open("temp.log"," r ") as ips=[] f: #读取小文件temp.log中的IP地址
for line in f:
ip=line.split()[0]
ips.append(ip) #将IP地址逐行追加到列表ips中
#调用showmax函数
Prin t("出现次数最多的 IP 是: ",a[0]," 出现次数为: ",a[1])