
s1=input("请输入明文:")
q="1357902468" ; s2=""
for ch in s1:
if "0"<=ch<="9":
s2+=q[int(ch)]
elif "a"<=ch<="z":
s2+=chr((ord(ch)-ord("a")+2)%26+ord("a"))
else:
s2+=ch
print(s2)
运行该程序,输入s1 的值为"Mike521@qq.com",则输出结果为 ( )
#将姓名和身份证号存储在二维数组 sfzh 的代码略
for i in range(len(sfzh)):
s=
year=s[:4]; month=s[4:6]; day=s[6:]
print("%s 同学的生日是:%s 年-%s 月-%s 日"%(sfzh[i][0],year,month,day))
划线处代码正确的是( )
import random
a = []
for i in range(6):
a.append(random.randint(1,5)*2+i%2)
for i in range(1,5):
j = i; k = a[j]
while a[j-1]<k and j>0:
a[j] = a[j-1]; j=j-1
a[j] = k
 图-1
图-1
 图-2
图-2
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #正常显示汉字
df=pd.read_excel('学考成绩.xlsx')
df.折算分=
#对df 以“班级”为主要关键字升序、“A 总数”为次要关键词降序进行排序
df_sort=df.sort_values(['班级','A 总数'],ascending=[True,False])
result=df_sort.head(5)
for i in range(2,7):
result=result.append( .head(5),ignore_index=True)
result.to_excel('各班前5名统计.xlsx')
df=df[df.折算分>92]
df_count=df.groupby('班级').count()
#修改“折算分” 列名为“上线人数”
df_count = df_count.rename(columns={'折算分':'上线人数'})
x=df_count.index
y=
plt.figure(figsize=(8,4))
plt.bar(x,y, label='上线人数')
plt.ylim(15,30)
plt.legend()
plt.show()
输入数据:将原图的每个像素的RGB灰度值存入二维数组img中;
处理数据:如果一个像素的RGB灰度值大于或等于阈值,则将该像素RGB灰度值设置为1,否则设置为0;
输出数据:将处理后的数据以图像形式呈现。
例如:部分图像二值化过程图-1所示。
 图-1
图-1
请回答下列问题:
| from PIL import Image import numpy as np import matplotlib.pyplot as pl img=np.array(Image.open('deer.jpg').convert('L')) key=int(input('请输入设定阈值: ')) rows,cols=img.shape for i in range(rows): for j in range(cols): if : #每个像素灰度值与阈值进行比较 img[i,j]=1 else: img[i,j]=0 |
#图像输出程序略
 图-2
图-2
 C .
C . 
①将明文中每个字符转换成其对应的十进制ASCII码值;
②明文的密钥由0-7这8个数字循环产生,如图-1所示;
 图-1
图-1
③加密过程中,先将每个明文字符的十进制ASCII码值转换成8位二进制数,再将每个字符对应的密钥转换为4位二进制数,最后,将由明文字符的十进制ASCII码值转换成的8位二进制数中的左边4位二进制数和右边4位二进制数,分别和由密钥数字转换成的4位二进制数逐位进行异或运算:1⊕1=0,1⊕0=1,0⊕1=1,0⊕0=0。
例如:明文字符串“Programming”中字母“a”用二进制表示是01100001,其对应的密钥是数字5,用二进制表示是0101,加密后结果是00110100,如图-2所示。
 图-2
图-2
④将每个字符的加密结果按行输出,如图-3所示。请回答下列问题:
|
s=input("输入待加密的原文: ") k=0 ; s1="" ; s2="" print("加密结果为: ") for i in range(0,len(s)): ch= ord(s[i]) m=k for j in range(0,4): t1=str((ch%2+m%2)%2) t2= s1=t1+s1 ; s2=t2+s2 ch=ch//2 ; m=m//2 print(s2+s1) s1="" ; s2="" |
图-3 |
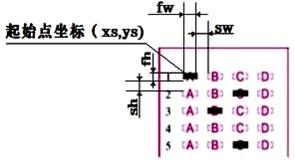
from PIL import Image
#输入起始点坐标(xs,ys),信息点宽度高度(fw, fh),间隔宽度高度(sw ,sh),代码略
num = 5 #判分个数
def bw_judge(R, G, B): # bw_judge用于判断一个像素的填涂情况
代码略
def fill_judge(x, y): # fill_judge用于判断信息点的填涂情况
count = 0
for i in range(x, x + fw + 1):
for j in range(y, y + fh + 1):
R, G, B = pixels[i, j]
if bw_judge(R, G, B) = = True:
count = count + 1
if count >=:
return True
total_width = fw+ sw
total_height = fh + sh
image = Image.open("t2.bmp")
pixels = image.load()
number = ""
bz=[""]*num
df=0
bzd=input('请输入标准答案:')
da={"A":"1000","B":"0100","C":"0010","D":"0001"}
for i in range(len(bzd)):
bz[i]=
for row in range(num):
for col in range(4):
y = ys + total_height * row
if fill_judge(x, y) == True :
number = number + '1'
else:
number = number + '0'
if number = = bz[row]:
df+=2
number=""
print("得分为: ",df)
#分数判定

