宁波公共自行车是宁波市推出的公共自行车服务,用于解决公共交通中的“最后一公里”问题。 市民可通过具有租车功能的甬城通卡借还公共自行车。租车时,在公共自行车锁止器的刷卡区域刷 卡,听到“滴”声后,锁止器打开,市民就能轻松取车。
另外还推出了宁波公共自行车app,市民通过该app加手机验证码就可以安全租赁公共自行车,免去办卡等辅助的手续,更好的保障个人信息安全,并且提供宁波公共自行车网点信息查询,以及相关资讯服务。
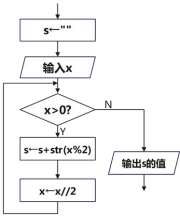
mingwen=input("请输入明文:")
miwen=""
for i in mingwen:
if "0"<=i<="9" :
miwen += str((int(i)+3)%10)
else:
miwen += i
print(miwen)( )
def isprime(x) :
for i in range(2,x) :
if x % i == 0 :
return False
return True
prime = []
for m in range(2,19):
if isprime(m) :
prime.append(m) #将 m 追加到列表 prime 中
print(len(prime))
程序运行后,输出的结果是( )
s = input("请输入一串字符串:")
f = True
for i in range(len(s)//2) :
if s[i] != s[len(s)-i-1] :
f = False
break
print(f)
若执行该程序后,输出的结果是“True”,则输入的字符串可能是( )
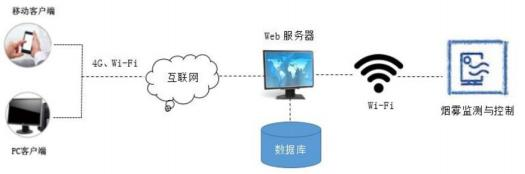
⑴利用micro:bit结合烟雾传感器对室内烟雾浓度进行监测。
⑵通过串口采集传感器的数据变化,实时传输到Web服务器并保存到数据库中,以便后续进行分析。
⑶使用者可对监测系统进行相关的设置,限定室内烟雾浓度的临界值。一旦指标高于所限定的临界值,系统将自动发出警报并开启水泵浇水。
系统通过智能终端每隔1分钟采集一次室内环境烟雾浓度数据。其架构示意图如图所示:
智能终端的部分程序代码如下:
#设置连接服务器参数并与智能终端建立无线连接,代码略
while True:
① = pin0.read_analog()
errno,resp = Obloq.get("input?id=1&val="+str(fog),10000)
if errno == 200:
display.scroll(resp)
if resp == '1':
pin8.write_digital(1) #打开蜂鸣器发出警报
pin16.write_digital(1) #打开继电器开启水泵浇水
else:
pin8.write_digital(0) #关闭蜂鸣器
pin16.write_digital(0) #关闭继电器
else:
display.show (str(errno))
② #设置数据采集间隔时间
服务器端部分程序代码如下:
from flask import Flask, request
import sqlite3
DATABASE ='tdata.db'
app = Flask(__name__)
@app.route("/")
def index():
#代码略
@app.route("/input",methods=["GET"])
def mytest():
#获取传感器 id 值和环境烟雾浓度值并存储在数据库中
#烟雾浓度超过最大值返回“1” ,否则返回“0”,代码略
if __name__ == '__main__':
app.run (host="192.168.1.8",port=8080,debug=True)
①②
 图 a
图 a
为了统计分析出每一小题的答题情况,小王编写了Python 程序,请回答下列问题:
import pandas as pd 第 1 小题
import matplotlib.pyplot as plt A: 2.22 %
plt.rcParams[("font.sans-serif")]= ["KaiTi"] B: 6.67 %
df=pd.read_excel ("ITdata.xlsx") C: 80.0 %
stunum=len(df) D: 8.89 %
for i in range(1,13): 第 2 小题
print("第"+str(i)+"小题") A: 0.0 %
for k in "ABCD" : B: 80.0 %
|
print(k+":",round(len(t)/stunum*100,2),"%")
该程序段运行结果的部分界面如图b 所示。
 图 b
图 b
画线处填入的代码为 (单选,填字母)
 图 c
图 c
sans="CBCABCABDABD"
qnum=list(df.columns)
for i in df.index :
=
#本次单选题的标准答案
for j in range(2,14):
if df.at[i,qnum[j]]== :
r=2 else:
r=0
#回答正确得 2 分
#回答不正确得 0 分
df.at [i,qnum[j]]=r
aver= []
for j in qnum[2:]: #统计各单选题的平均分
aver.append( )
plt. (qnum[2:],aver,label="平均分")
plt.legend()
plt.show ()
import random
def mk(num) :
x= [0]*num #创建列表 x= [0,0,……,0],其中 0 的个数是 num
x[0]=random.randint(5,10) #randint(a,b)返回[a,b]区间内的一个随机整数
for i in range(1,num) :
![]()
return x
m=n=5
a=mk(m)
b=mk(n)
print("原始数据序列 a 为:",a)
print("原始数据序列 b 为:",b)
①使用语句 a= mk(5)调用函数,加框处语句的执行次数是 (填写阿拉伯数字) 。
②执行上述代码后,关于输出的列表a、b 中的数据,下列说法正确的是 (单选,填字母: A .相同 / B .不相同 / C .可能相同)
| b[0] | b[1] | b[2] | b[3] | b[4] |
| 10 | 11 | 15 | 16 | 17 |
为了使合并后的数据保存在列表a 中,现对列表 a 扩充 n 个元素“-1”,扩充后状态如下:
| a[0] | a[1] | a[2] | a[3] | a[4] | a[5] | a[6] | a[7] | a[8] | a[9] |
| 7 | 9 | 10 | 14 | 19 | -1 | -1 | -1 | -1 | -1 |
变量i赋值为0,指向列表b的首数据,变量p赋值为0,指向列表a的首数据,变量tot指向列表a的最后一个有效数据(如图所示) 。

合并的具体算法如下:
Ⅰ.如果 a [p]= – 1 ,则直接将 b[i]存储到 a [p]中,同时 tot 值增加 1;
Ⅱ.如果 a [p]>b[i] ,则整体将 a [p] ,… ,a [tot]向右移动一个位置,然后将 b[i]存储到空出的位置, 同时 tot 值增加 1。
Ⅲ. p 值增加 1;
小强编写的合并代码如下,请在划线处填入合适代码。
#将列表a 的数据个数存入m,列表b 的数据个数存入 n,代码略
#对列表 a 扩充 n 个-1,代码略
p=0
tot=
i=0
while : #将列表b 中元素 b[i]逐个插入到列表 a 中
if a[p]==-1 :
a[p]=b[i]
tot+=1
i+=1
elif a[p]>b[i] :
for j in range(tot,p-1,-1): #整体将 a[p], … ,a[tot]向右移动一个位置
a[j+1]=a[j]
tot+=1
i+=1
p+=1
print("合并后的数据序列为:",a)
