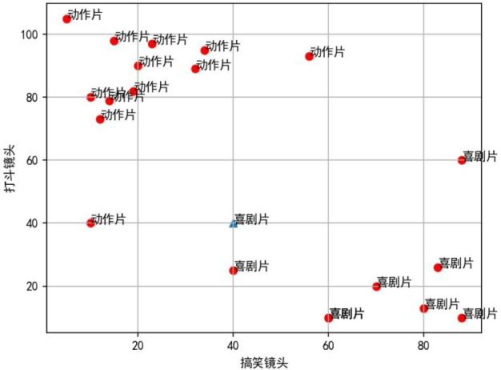
例如:
①输入搞笑镜头40和打斗镜头40:
②计算点(40,40)和其余所有点的距离(两点间的距离计算公式:
③将所有样本按照距离排序;
④假设k=3,取前k个距离的样本;
⑤统计出在前k个距离中,出现频次最多的类别,则(40,40)就属于该类别,可能是喜剧片。
x=int(input('请输入搞笑镜头数:'))
y=int(input('请输入打斗镜头数:'))
d=[ ] #用于存储距离
#已将所有样本横坐标保存至列表 ybx,可用 ybx[i]表示某一点横坐标
#已将所有样本纵坐标保存至列表yby,可用yby[i]表示某一点纵坐标
#即样本点坐标可用(ybx[i],yby[i])表示
for i in range(len(ybx)): #通过循环,计算所有样本点到点(x,y)的距离
d[i]=
(提示:sqrt()函数为开根函数,sqrt(3)即为根号 3)


