import pandas as pd #引入pandas 模块
import matplotlib.pyplot as plt #引入matplotlib 的pyplot 子库
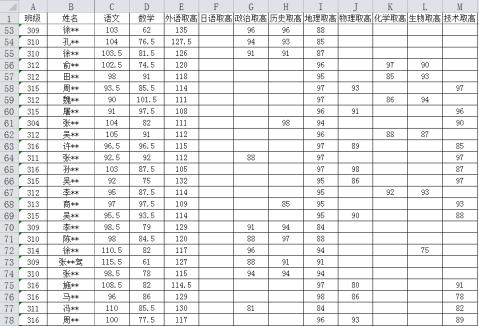
df=pd. ('cj.xlsx') #读取"cj.xlsx"文件中的数据,创建DataFrame 对象df
# 若要筛选本次考试数学分数超过120分且技术分数到达88分及以上的学生并输出他们的考试情况 (df1中保存筛选结果,提示: 多条件筛选时,与(and) 关系用“&”连接, 或(or) 关系用“|”连接)
df1 = (单选, 填字母)
print (df1)
A.df[(df["数学"] >= 120 )&(df["技术取高"] >= 88)]
B.df[(df["数学"] > 120 )&(df["技术取高"] >= 88)]
C.df[(df["数学"] > 120 ) | (df["技术取高"] >= 88)]
D.df[(df["数学"] >= 120 ) | (df["技术取高"] > 88)]
# 若要了解该校参加该次考试选考各科的选课人数,请完善下面的代码。
for km in df.columns[6:13]:
renshu = ;
print("选",km,"的人数为:",renshu)
# 想要了解该校技术班级数学科的平均分,并绘制一个图表, 针对各班数学平均分进行比较分析 df2 = df.groupby("班级",as_index = False).mean()
df3 = df2.sort_values("数学", ) # 通过排序使得按平均分降序排序并存储在 df3 中 plt.bar (df3.班级, df3.数学 )
plt.title("班级数学平均分比较")
plt.xlabel("班级")
plt.ylabel("数学平均分")
plt.show ()


