全球气候变暖以及海水温度升高,导致珊瑚礁出现大片白化现象。珊瑚白化,是由于海水温度升高造成的。以往对珊瑚礁健康状况的监测主要靠人力完成,分析过程费时费力。现在,科学家们训练了一个人工智能(AI)系统,可以根据声音记录对珊瑚礁的健康状况进行分析。他们分别使用健康和退化珊瑚礁的大量声音记录训练了一种计算机算法,使机器能够学习两者之间的差异,随后分析了数百个小时的声音记录,快速便捷地识别出了珊瑚礁的健康状况,准确率不低于92%。
①变量s的初值为0,f的初值为-1,变量i的初值为2
②若i不超过10,则执行③,否则执行⑤
③s>s+f*i*(i+2),f>-f
④将i的值增加2,返回②
⑤输出变量s的值
则下列说法正确的是( )

dic={"苹果":[9.98,12.98],"香梨":[8.98,16.98]}
dic["苹果"][1]=15.98
dic["葡萄"]=[12.58,13.98]
print(dic)
该程序运行后输出的结果为( )
s=pd.Series(range(70,100,10))
for i in s:
print(i)
该程序运行后输出的结果为( )
 C .
C .  D .
D . 
他编写了一个 Python 程序,检测学习情况,代码如下:
f=open("word.txt","r")
line=f.readline()
word=[]
while line:
temp=line.split() #将字符串以空格为分隔符号进行分割, 并存储在列表中
for i in temp:
if i[0]=='c' and 'e' in i:
word.append(i)
line=f.readline()
print(word)
执行该程序段后,输出的英语单词个数为( )
for i in range(100,0,-1):
flag=True
m=i
for j in range(len(a)-1,-1,-1):
if m % 2!=a[j]:
flag=False
m//=2
if flag:
ans=i
break
print(ans)
已知列表a=[1,0,0,0,1,0,1],程序运行后,变量ans的值是( )
defrepeat(s,x,y):#判断字符串s从位置x到y是否有重复字符
#无重复返回True(若x=y,为无重复),有重复返回Flase,代码略。
s1=input("请输入一个数字字符串: ")
len=len(s1)
left,right,maxlen=0,0,0
while right<len:
if not repeat(s1,left,right):
⑴
else:
if ⑵ :
maxlen=right-left+1
s2=s1[left:right+1]
⑶
print("最长无重复子串为: ",s2,"长度是: ",maxlen)
加框处的可选代码为:
①left+=1 ②right+=1 ③right-=1
④right-left>maxlen ⑤right-left+1>=maxlen
为使程序正确运行, 则程序段(1)(2)(3)处代码依次为( )

from PIL import Image
im = Image.open("white.jpg")
pix = im.load()
width = im.size[0] #获取图像宽度值
height = im.size[1] #获取图像高度值
for x in range(width):
for y in range(height):
if x<=width//2 and y<=height//2:
if x%50==0 or y%50==0 :
pix[x,y]=(0,0,0)
elif y>height//2:
if x==y or width-x==y :
pix[x,y]=(0,0,0)
im.show ()
white.jpg
程序执行后的图像效果是( )
 B .
B .  C .
C . 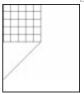 D .
D . 
|
图 a |
import pandas as pd
import matplotlib.pyplot as plt
plt.rc("font", **{"family": "SimHei"}) #设置中文字体
df1=pd.read_excel ("wrong.xlsx")
df1["得分"]=26-df1.sum(axis=1)*2
for i in df1.index:
if :
df1.at[i,"学号"]="*"+df1.at[i,"学号"]
print( ) #输出满分的同学
wnum={}
for i in df1.columns[1:14]:
wnum[i]=num
print(wnum) #输出结果如图b所示
| {'单选 1': 11, '单选 2': 3, '单选 3': 3, '单选 4': 4, '单选 5': 5, '单选 6': 2, '单选 7': 9, '单选 8': 10, '单选 9': 7, '单选 10': 19, '单选 11': 9, '单选 12': 13, '单选 13': 26} |
图b
#根据错误人数进行排序
df2=pd.DataFrame({"题号":wnum.keys( ),"错误人数":wnum.values( )})
df2_sort=df2.sort_values('错误人数', )
print(df2_sort) #输出结果如图c所示
#创建图表,分析错误人数最多的前6个单选题
df3 = df2_sort.
plt.title("错误人数排名前 6 的单选题")
plt.bar ![]()
plt.ylim(5,30)
plt.legend( )
plt.show ( )
|
|
图 c
|
图 d |
![]()
import math
def isprime(n):
for i in range(![]() ):
):
if n%i==0:
break
else:
return True
return False
cicada=[]
c=0
for i in range(13579,99999,2):
a=[0]*10
temp=i
while temp!=0:
temp//=10
if a[1]+a[3]+a[5]+a[7]+a[9]==5:
x=i//100%10
y=
if and isprime(y) and isprime(i):
cicada.append(i)
c+=1
print("金蝉素数有: ",cicada)
print("共有:",c,"个")
①将明文字符串分成3个字符一组,对每组字符进行②③处理,剩余不足3个的字符不做处理。
②随机产生由26个不重复的小写英文字母组成的密文串,将明文中的每组字符分别替换为密文串中对应的字符,若密文串如表1所示,则明文“abcdefghijkl”替换为“jpgntkwmaery”。
|
小写字母 |
a |
b |
c |
d |
e |
f |
g |
h |
i |
j |
k |
l |
m |
n |
o |
p |
q |
r |
s |
t |
u |
v |
w |
x |
y |
z |
|
密文串 |
j |
p |
g |
n |
t |
k |
w |
m |
a |
e |
r |
y |
l |
d |
c |
q |
f |
i |
x |
u |
h |
z |
b |
o |
v |
s |
表 1
③输入一串数字密钥(由1~9数字组成),密钥中每个数字依次为每组字符向右旋转次数,若密钥长度不足,则重复使用密钥,数字与对应旋转次数见表2。例如,数字密钥为“45”,则将第1组字符向右旋转1次,如“jpg”>“gjp”,将第2组字符向右旋转2次,如“ntk”>“knt”>“tkn”,第3组字符向右旋转1次,第4组字符向右旋转2次,依次类推。
|
数字 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
旋转次数 |
1 |
2 |
3 |
1 |
2 |
3 |
1 |
2 |
3 |
表 2
④将每组处理后的字符串顺序连接, 每组之间用“*”作为间隔符号, 再将分组剩余的字符倒序 连接, 得到密文。
程序运行结果如下:




