
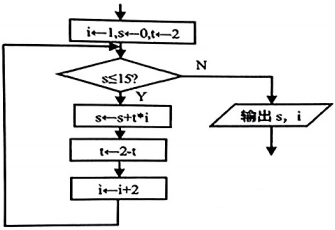
某智慧食堂是基于政府机关、企事业单位、医院、学校等食堂管理模式,创新打造的 食堂订餐及就餐模式。系统具备强大的管理功能,如下图所示。
|
在 线 预 订 |
聚 合 支 付 |
餐补管理 |
营 养 卫 士 |
Al智 能 结 算 |
|
PC 端移动端微信打钉 |
人脸识别扫描刷卡 |
五种幅补账户幅补标准 |
菜品营养提示终端 |
视觉识别菜品自动核算 |
|
15种订幅方式 |
多种账户支付 |
可定制可对接人资系统 |
查询就幅营养分析 |
刷脸结算离线部署 |
|
RFID 芯 片 结 算 |
智能称重结算 |
食品安全管理 |
进 销 存 管 理 |
经 营 统 计 分 析 |
|
缩短排队时间自助刷卡 |
智能秤称重精确到克 |
食品留样菜品湖源 |
原料反算采购计划 |
财务统计订单管理 |
|
快速核算避免漏账 |
自动整单计算营养指导 |
明厨亮灶农残检测 |
供应商管理进销存管理 |
消费汇总日销菜品统计 |
|
集 团 管 控 |
大屏云监管 |
后厨行为监控 |
食堂环境监测 |
就 餐 客 流 监 测 |
|
统一管理跨区域满费 |
就幅数据菜品数据 |
手机监控后厨行为 |
温湿度、 一氧化硫, |
人流信息实时监测 |
|
经营监管集中采购 |
分析用户满意度 |
违规短信提蛋 |
燃气泄漏等多雄度监测 |
指引错峰就餐 |
m=0
elif t<=3*60:
m=5
else:
m=5+(t3*60+59)//60
B . if t>30:m=5
if t>3*60:
m=5+(t-3*60+59)//60
else:
m=0
C . m=5if t>3*60:
m=5+(t-3*60+59)//60
elif t<=30:
m=0
D . m=0if t>3*60:
m=5+(t-3*60+59)//60
if t>30:
m=5
max1=max2=0
for i in range(len(1st)):
if lst[i]>max1:
⑴
⑵
elif lst[i]>max2:
⑶
print("最大值是:"+str(max1)+",次大值是:"+str(max2))
上述程序段中划线处可选语句为:
①max1=1st[i] ② max1 = max2 ③max2 = max1max2 =1st[i]
则(1)、(2)、(3)处语句依次可为( )
import random
a=[0]*6
i=0
while i<6:
a[i]=random.randint(1,5) #元素值在1到5之间
if a[i]%2!=i%2:
i-=1
elif i%2==1:
a[i]+=a[i]-1
i+=1
print(a)
程序运行后,输出的a 不可能的是( )
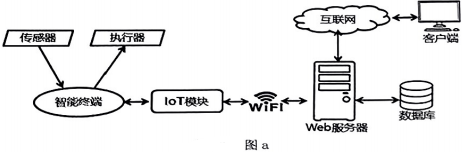
while True:
temp=round(pin2.readanalog()/1024*3000/10.24,1)
errno, resp=0bloq.get("input?id=1&val="+str(temp),10000)
if errno==200:
if resp=='1':
pin8.writedigital(1)
else:
pin8.writedigital(0)
else:
display.scroll(str(errno))
sleep(1000*300)
则温度传感器连接智能终端的端口是,温度传感器采集温度的时间间隔为 (填整数)分钟。
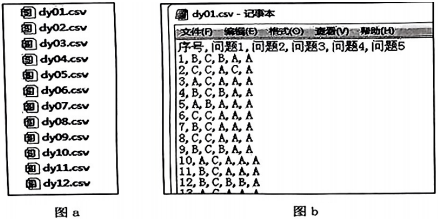
现需要分析12个班级学生对这5个问题的选“A”情况。谢老师用python的pandas模块编写了以下代码,实现相关问题的解决。请回答下列问题。
import pandas as pd
def fun A(file):
df=pd.read csv(file)
A list=[]
for i in df.columns[1:]:
j=0
c=0
while j<len(df):
if
c+=1
j+=1
A list.append(c)
return A list
ans list=[]
s=”010203040506070809101112"
for i in range(0,len(s)- 1,2):
filename="dy"++".csv"
res= fun A(filename)
ans list.append(res)
x=["问题1","问题2","问题3","问题4","问题5"]
y=[0,0,0,0,0]
for i in range(5):
s=0 #每个问题选A的人数
for j in range(12):
y[i]=s
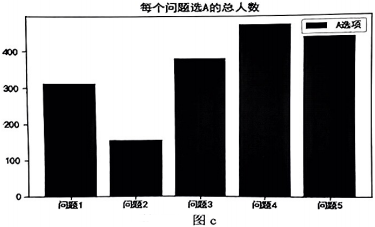
import matplotlib.pyplot as plt
plt.rcParams ['font.sans-serif']=['SimHei'] #图表显示中文字体
plt.title("每个问题选A 的总人数")
![]()
plt.legend()
plt.show()
加框处代码合适的是(单选,填字母)

def read(file):
f=open(file,'r') #读取文件
li=[]
for line in f:
s=''
for i in range(len(line.strip())): #strip()函数删除字符串末尾的“\n”
ch=line[i]
if ch==',':
flag=True
if ch>='0'and ch<='9'and flag:
s=s+ch
li.append(s)
f.close()
return li
def gl(s):
a=[]
for i in range(len(s)- 1):
x=s[i]
for j in range():
y=s[j]

return a
def maxgl(dic):
mt=0
for i in dic:
if dic[i]>mt:
return mt
dic={}
li=read('data.txt')#data.txt 是流水文件
for i in li:
if len(i)>1:
a=g1(i)
for j in a:
if j in dic:
dic[j]+=1
else:
dic[j]=1
mt=maxg1(dic)
for i in dic:
if
print('关联度最多的一组商品是: x'+i[0]+'和x'+i[1])
