12306是中国铁路客户服务中心网站,于2010年春运首日开通并进行了试运行。2013年12月,12306手机客户端正式开放下载。用户在该网站可查询列车时刻、票价、余票、代售点、正晚点等信息,并随时随地在手机上购买车票、完成支付,在自助设备上还能完成自助取票等流程。

def peach(n):
if n == 10:
return 1
else:
return (peach(n+1)+1)*2
print(peach(8))
执行该程序段后,输出的结果是( )
s = "abcxyz"
q = [1,2,3] + [0] * 10
head , tail = 0 , 3
res = ""
for i in s :
c = chr ((ord(i) - ord("a") + q [head]) % 26 + ord("a"))
res += c
q [tail] = q [head]
head = head + 1
tail = tail + 1
print(res)
执行该程序段后,输出的结果是( )
import random
a = [1,3,4,6,6,6,9,9,11,12]
key = random.randint(2,5) * 2
i,j = 0,9
while i <= j :
m = (i + j) // 2
if key < a[m]:
j = m - 1
else:
i = m + 1
print(j)
执行该程序段后,输出的结果不可能是( )
A .2 B .3 C . 5 D . 7
tmps = [32,28,26,29]
n = len (tmps) ; top = -1
an s = [0] * n
stk = [-1] * n
for i in range(n):
t = tmps[i]
while top > -1 and t > tmps[stk[top]] :
d = stk[top]
top -= 1
an s[d] = i - d
top += 1
stk[top] = i
print(an s)
执行该程序段后,输出的结果是( )

| 序号 | 访问地址 | 功能说明 |
| 1 | / | 实时显示最新数据 |
| 2 | /input?tem=20&light=40 | 提交传感器数据 |
| 3 | /search | 查看显示某一天的历史数据 |
若要查看某一天的数据记录,在浏览器应输入的 URL 为。
for i in s :
if s[i] < tmin or s[i] > tmax:
c += 1
print("超过适宜温度的次数",c)
B . c = 0for i in range(len (s)) :
if tmin <= s[i] <= tmax:
continue
c += 1
print("超过适宜温度的次数",c)
C . c = 0;i = 1while i <= len (s) :
if not(tmin <= s[i] <= tmax) :
c += 1
i += 1
print("超过适宜温度的次数",c)
D . c = [0]*len (s)for i in range(len (s)) :
if not(s[i] >= tmin and s[i] <= tmax):
c[i] = 1
print("超过适宜温度的次数",sum(c))
def cal(s) :
n = len (s)
for i in range(n):
if s[i] == " " : #如果为空格字符
p = i
if s[i] == " :" :
q = i
t = + int(s[q+1:])
return t
 图 b
图 b
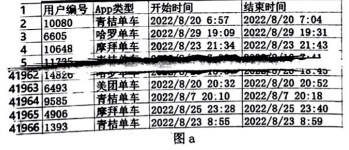
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel("shared bikes.xlsx")
bike = [ "哈罗单车","摩拜单车",
"美团单车","青桔单车"]
sm = [0] * 4
avg = [0] * 4
days = 31
for i in :
t = cal(df.at[i, "结束时间"]) - cal(df.at[i, "开始时间"])
for j in range(4):
if df.at[i, "App 类型"] == bike[j] :
break
for i in range(4):
avg [i] = sm[i] / days
plt.figure(fig size = (12,4))
x = bike
y =
plt.bar (x,y)
plt.show()
n = df.groupby ("App 类型", as_index = True).用户编号.![]()

def wordlist(data,info) :
n = len (data)
for i in range(n):
data[i].append(-1) #data[i]追加一个元素-1
for i in range(n):
d = data[i][0]
if info[k] == -1:
info[k] = i
else:
head = info[k]
q = head
while :
p = q
q = data[q][2]
if q != head:
data[p][2] = i
data[i][2] = q
else:
data[i][2] = head
return data,info
def searchword(data,info,key) :
k = ord(key [0]) - ord("a")
head = info[k]
p = head
while p != -1:
if data[p][0] == key:
return
p = data[p][2]
return "没有找到该单词"
读取词汇数据库,存入列表 data 中,列表的每个元素包含 2 个数据项,分别为英文单词和中 文翻译,如 data = [[‘audio ’,‘音频 ’], [‘binary ’,‘二进制数 ’] …], 数据读取 存入的代码略。
'''
info = [-1] * 26
data,info = wordlist(data,info)
key = input("请输入查找单词:").lower () #转化为小写字母
res = searchword(data,info,key)
print(key, "查找结果是:", res)
