某高中建成了智慧校园信息系统,通过人脸识别完成身份认证,可以实现进出校园、图书借阅、家校沟通、在线学习等活动。
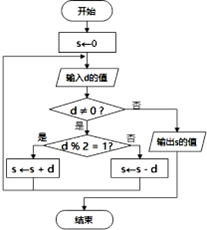
#通过传感器获取鱼缸内水温值,并存储到变量t中
LED="绿色"
if :
if t>32:
LED="红色"
else:
LED="蓝色"
print("LED 灯颜色显示:",LED)
为实现上述功能,划线处正确的Python表达式是( )
#某次测试的语文、数学成绩被存储在变量score中
score={"语文":[117,105,103,110,105,100,98],"数学":[97,119,113,139,129,124,132]" }
count=0
for i in range(7):
if _____________ >115:
count+=1
print("数学成绩大于 115 分的人数",count)
为实现上述功能,划线处正确的Python表达式是( )
s="JiaYou2191" ; ans=""
for ch in s:
if "0"<=ch<="9":
ch=str((int(ch)+1)%10)
ans=ch+ans
else:
if "a"<=ch<="z":
ch=chr(ord(ch)-ord("a")+ord("A"))
ans+=ch
print(ans)
执行该程序段,输出的结果是( )
i=1;k=-1
sum=i
while i<100 :

print(sum)
方框中的代码由以下三部分组成:
①i+=1 ②k=-k ③sum+=k/i
下列选项中,代码顺序正确的是( )
def pell(n):
if n<=2:
k=n
else:
k=pell(n-1)*2+pell(n-2)
return k
n=int(input("n="))
print(pell(n))
执行该程序段,当输入的值为5时,输出的结果是( )
|
1 图 |
2 图 |
3 图 |
 B .
B . 
b = [0,0,0,0,
0,0,0,0,
0,0,0,0,
0,0,0,0 ] # 表示 4×4 方阵
time = input("输入时间(例:08:25 输入 0825):")
for i in range(len(time)):
n =
r2 = ""
for j in range(4): # 将数字转为 4 位二进制
r2 =
n //= 2
for j in range(len(r2)):
if r2[j] == "1":
b[j * 4 + i] = 1
s = ""
print(time, "模拟结果:")
for i in range(len(b)):
s += str(b[i]) + " "
if :
print(s)
s = ""
信息社团的两个小组收集了不同年级学生点餐及菜品评分的数据,数据集合用“数据集A”与“数据集B”来表示,分别存储在“数据集A.xlsx”与“数据集B.xlsx”文件中,如1图、2图所示:
|
1 图 数据集 A.xlsx
2 图 数据集 B.xlsx |
①将“数据集B”中的“★”评价转换为数值评分
②舍弃“数据集B”中“年级”列数据
③修改“数据集A”中“序号”列数据,从1开始递增
④合并“数据集B”至“数据集A”
下列选项中,操作顺序正确的是( )(单选,填字母)
|
|
编写Python程序实现上述功能:
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel ("数据集 A.xlsx")
df = ![]()
plt.rcParams['font.sans-serif']=['SimHei'] #正常显示中文标签
plt.figure(figsize=(15,5))
x=df.菜品名称
y= _________________
plt.bar (x,y)
plt.title("菜品评分情况")
plt.xlabel("菜品名称")
plt.ylabel("平均评分")
for i,j in zip(x,y): #设置图表标签
plt.text(i,j+0.05,'%0.2f'%j,ha='center')
plt.show ()
加框处代码应为( )(单选,填字母)
|
1 图 |
|
|
import pandas as pd
df=pd.read_excel ("数据集 A.xlsx")
cp=["小炒时蔬","红烧牛肉","黄焖鸡","红烧肉","粉蒸肉","梅菜扣肉","糖醋排骨 ","烧圆子","小炒肉","水煮肉片","香菇炒肉","鱼香肉丝","烤鸭","香酥鸭","烧 带鱼","炸小鱼","大锅菜","番茄鸡蛋","麻婆豆腐","凉拌黄瓜"]
cpdic={"小炒时蔬":0,"红烧牛肉":1,"黄焖鸡":2,"红烧肉":3,"粉蒸肉":4,"梅菜扣 肉":5,"糖醋排骨":6,"烧圆子":7,"小炒肉":8,"水煮肉片":9,"香菇炒肉":10,"鱼香 肉丝":11,"烤鸭":12,"香酥鸭":13,"烧带鱼":14,"炸小鱼":15,"大锅菜":16,"番茄 鸡蛋":17,"麻婆豆腐":18,"凉拌黄瓜":19}
a=[]
for i in df.values:
# 列表 a 分别存储订单编号、菜品 id、菜品名称
a.append([i[2],i[4],i[5]])
n,ncp=len(a),len(cp)
num=[0]*ncp
j=0
cpmc=input("请输入菜品:")
key=cpdic[cpmc] # 通过菜品名称获取菜品 id
while j<n:
if j==0 or a[j-1][0]!=a[j][0]:
start=j
if a[j][1]==key:
while a[j][0]==a[start][0]:
if start!=j:
num[ ]+=1
start+=1
if start==n:
break
![]() # 改错
# 改错
j+=1
for i in range(3): # 输出三个套餐搭配建议
for j in range(ncp-1,i,-1):
if :
num[j-1],num[j]=num[j],num[j-1]
cp[j-1],cp[j]=cp[j],cp[j-1]
print("建议套餐中包含",cpmc,"与",cp[i],",两个菜品关联次数为",num[i])

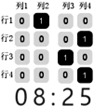




 3 图
3 图
 2 图
2 图